Efficiently Expose Services on Kubernetes (part 1)
Learn about Kubernetes Pods, the basic compute units running containers, with their cluster-private IP addresses enabling communication between containers. Explore the challenges of directly accessing Pods due to potential IP address changes and their unreliable nature. This blog delves into Kubernetes objects for network exposure, their limitations, and Stakater's efficient tools and practices for scalable Kubernetes service exposure.
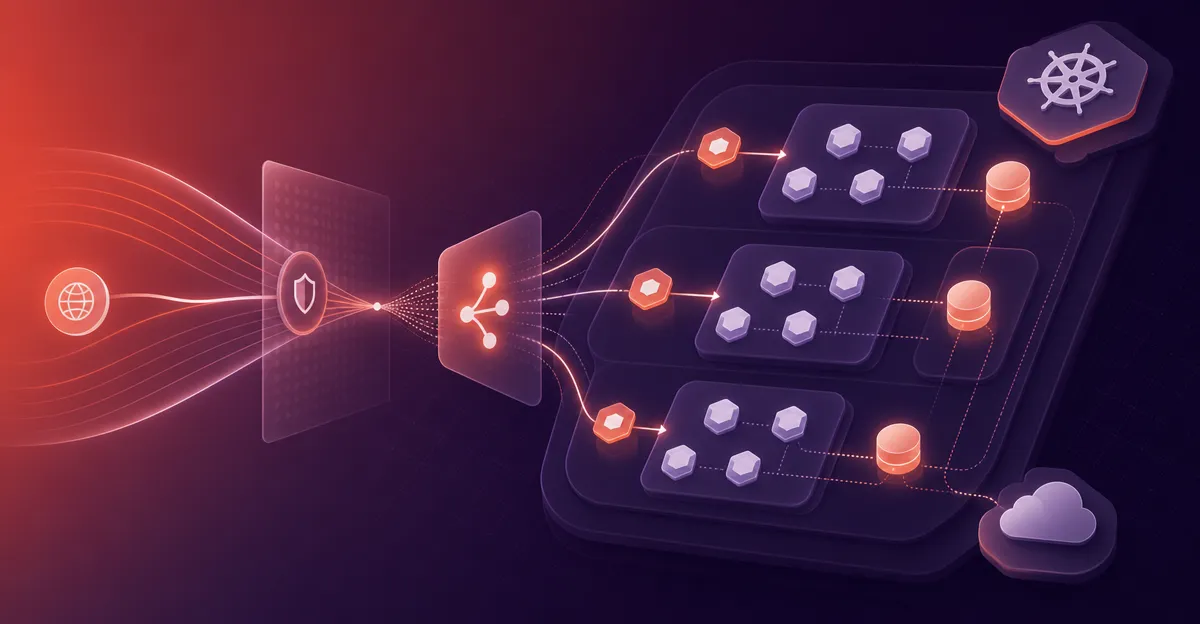
A Pod is the lowest compute unit in Kubernetes running one or more containers. Pods have their own cluster-private IP address, which means that containers within a Pod can all reach each other’s ports on localhost, and all pods in a cluster can see each other. However, Pods can die, whether crashing, rolling update or being removed due to downscaling, in which cases, their IP addresses change. Therefore directly accessing pods is not a reliable way to access the application. In this blog, we will first look at the objects that Kubernetes provides out of the box that are required to expose the applications over a network, and some of the restrictions that they have. Following that we will review some of the tools and practices we at Stakater use to efficiently expose Kubernetes services in a scalable way.
Services
Services are Kubernetes objects that provide a reliable way to access applications running on the pods. Services are what make pods consistently accessible. Services connect Pods together or provide access outside of the cluster. Pods can now be created, destroyed or recreated, and have their IPs changed in the process but a service will maintain knowledge of these and anyone trying to access the application only needs to know about the service, and need not know about how many pods are running, or what any of their IP addresses are. Services will use a selector to identify which pods it needs to connect to. So in case, a pod is recreated or the number of pods is scaled up and more pods are added, the service will connect to these pods as well as long as they have the relevant selector applied to them.
When created, each Service is assigned a unique IP address (also called clusterIP). This address is tied to the lifespan of the Service, and will not change while the Service is alive. Pods are connected to Services using labels, and Services provide automatic load-balancing across these pods.
Service Types
There are several service types that can be used to expose apps for different requirements.
ClusterIP
The ClusterIP service type is the default and only provides access internally on a cluster internal IP. Not exposing a service outside the cluster is not very useful, so this service type can be used for accessing internal traffic only or for debugging etc. It can however be used with other kubernetes resources, which will be useful as we will see in the upcoming section.
NodePort
The NodePort type exposes the service on a static port on each node. Each Node proxies that same port number on every Node into the Service. This type of service does expose the app to the outside world, however, it is only good for short term public access or for debugging, and not recommended for production applications. The disadvantages being, that we can only have one service per port, there is a limited number of ports we can use, and there needs to be special handling for cases of the Node IP changing, which may happen quite often in a continuous deployment environment.
LoadBalancer
The LoadBalancer service exposes the app using a cloud provider’s load balancer. The external load balancer directs the traffic to the backend Pods. At first glance, this seems quite a convenient way to expose your apps. A couple of caveats are that all traffic on the port you specify will be forwarded to the service, and there is no filtering or routing. The major disadvantage however is that each service you expose will get its own IP address which will be handled by a separate Load Balancer. Having 1 Load Balancer per service will mean a skyrocketing cost in a large-scale application. To automate reloading of updated configurations in Kubernetes, you can utilize Reloader, a tool developed by Stakater.
Ingress
A more efficient way of exposing services is the use of Ingress. Instead of using lots of services, such as LoadBalancer, we can route traffic based on the request host or path using Ingress Controllers and rules. This allows for centralization of many services to a single point. We leave the services as ClusterIP types since they can connect to the Ingress, and define how the traffic gets routed to that service using an Ingress Rule. An ingress rule consists of an optional host, a list of paths, and a backend. The host and path are used to identify which host and path the rule applies to. And the backend identifies the service and port to direct the request to.
For an ingress resource to work, the cluster must have an ingress controller running.
Ingress controller
An Ingress Controller basically looks up Ingress resource definitions and routes traffic to services according to those definitions. An Ingress Controller can match with specific Ingresses based on a custom annotation specifying the ingress class.
At Stakater we use the Kubernetes-supported nginx ingress controller. Other community-supported controllers are also available. The controller automatically creates a Load Balancer, such as ELB in our AWS clusters. While one load balancer and ingress controller may be enough for a particular workload, from a security point of view, we follow the practice of having 2 ingress controllers and load balancers; one for public applications, an “external” ingress controller and the other for private applications, and “internal” ingress controller. The ingress class names are chosen to match their purpose. The two ingress controllers are deployed with the relevant ingress class as its configuration parameter. And any ingresses that are created as part of a deployment are annotated with the relevant ingress class as well.
With two ingress controllers in this configuration, we can run both public and private applications within a single cluster. But more importantly, this serves a security purpose while helping us in the automation of our deployment processes. While the public applications and load balancer should indeed be accessible from anywhere in the world, the private applications and load balancer should have restricted access as much as possible, and this is where security groups and IP whitelisting plays a role. These rules can be constantly applied to the private load balancer, and any private application that is being deployed in the cluster, need only be annotated with the internal ingress class. The service when deployed automatically becomes accessible online while still following security rules defined as per organization policy. Now, depending on the organization and policies, this idea can indeed be extended to even more ingress controllers and load balancers. In case there are multiple sub-organizations that must maintain some access boundaries, multiple ingress controllers and load balancers can be deployed with a meaningful ingress class. And all relevant ingresses will be accessible only from within the sub-organization’s origin network while filtering out requests from any other network.
Using Ingress controllers and Load balancers we can indeed expose our apps externally, but they will still be accessible by the load balancer’s dns name, which can be quite clunky and not at all easy to remember or write down. A custom DNS name is of course used for this purpose which can point to the load balancer instead. A DNS service such as Route53 in AWS can be used. Here is where another tool comes into play.
ExternalDNS
While DNS entries can be manually entered into the DNS provider such as AWS Route53, it is not a scalable way of doing things, especially considering we are using the same Ingress Controller and Load Balancer to serve traffic for multiple services and consequently domain names, that are being filtered and routed at the ingress level. DNS resolution is provided as a Kubernetes add-on in clusters. As services are created, they get automatically registered in DNS and the service can be referenced by name when being accessed from other pods or services. However, this is only an internal name server and does not cater to public DNS.
At Stakater we use the ExternalDNS project. This nifty tool automates DNS entries for our application deployments. ExternalDNS looks at the resources (Services, Ingresses, etc.) being exposed and determines the list of DNS records to be configured. It is DNS provider-agnostic and can be used with popular DNS providers such as AWS Route53. The tool keeps the DNS entries in sync with the cluster, which means not only does it add DNS entries for a new exposed app, but it also cleans up the entries when the app is removed from the cluster.
You can learn more about the importance of having a Kubernetes test environment and how to set it up in this blog post.
Conclusion
We have reviewed the Kubernetes objects we can use to expose applications on a cluster and also some of the tools and practices that we use at Stakater for efficiently doing so. When dealing with a microservices environment where there may be many multiples of microservices, configuration can become quite tedious and time-consuming. There are still some processes that can be automated further to make deployment even easier, which we will review along with the tools that make it possible, in the next part of this blog here.
For a comprehensive assessment of your platform, explore Stakater Kubernetes Platform Assessment.