Git Strategies for DevOps
Discover the importance of source versioning in software development and its role in DevSecOps automation. Explore how distributed source versioning systems like git offer agility and collaboration. Embrace git as the leading versioning system with various enterprise-grade services available. Experience the ease of creating, maintaining, and adapting code versions for different features and environments in a distributed versioning model.

Introduction
Source versioning is a core activity in software development. It is also a foundation of DevSecOps automation. With technologies such as cloud infrastructure, build tools, CI tools, the move to declarative configuration and environments, source versioning is being used for more than just application code. Distributed source versioning systems such as git are particularly suited to DevSecOps practices, as they provide a more agile and collaborative approach to source versioning. Git has become the defacto versioning system of today, with a multitude of enterprise-grade services available such as Github, Gitlab, Bitbucket, etc. In a distributed versioning system such as git, the repository can be cloned into multiple repositories, forked, branched, merged, to support a model where collaborators get a full copy of the code and can easily create new changes and maintain different versions of the code to suit different features and environments.
At Stakater we follow the best practices of implementing everything declaratively through code. This allows us to recreate any corrupt or destroyed environments with great ease. It also allows us to easily replicate environments and deployments for different environments or projects, e.g. implementing a monitoring tool stack like Ingress Monitor Control across different projects.
Versioning Strategy

First, let’s review the versioning strategy we use. Semantic Versioning (or SemVer for short) is a popular versioning methodology introduced to get rid of the problem of “dependency hell”, where versioning can become a hurdle to the easy and safe progression of a project. SemVer specifies an intuitive way to track and understand the versioning of a project and its dependencies and what to expect when moving from one version to another. This becomes quite useful not only for external dependencies but also in a microservices-based architecture when the project itself has multiple microservices each with its own version number. This in essence is what allows a microservices application development to be so agile and be developed in parallel across individuals or teams. In semantic versioning, a normal version number takes the form X.Y.Z where X is the major version, Y is the minor version, and Z is the patch number. More information on Semantic Versioning can be found here.
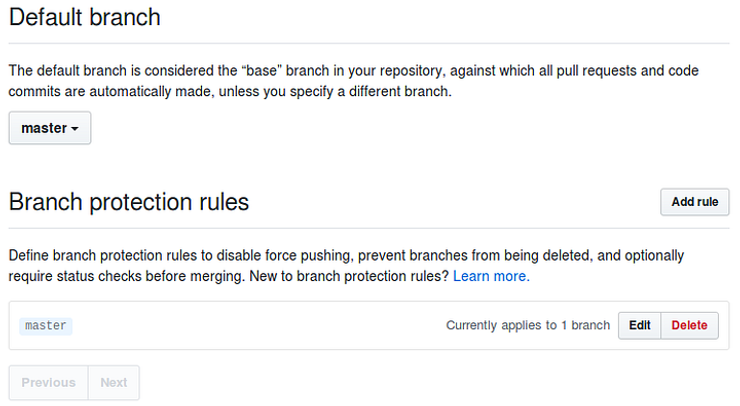
Branching Strategy
Any development starts with a development git branch. At Stakater, we follow a policy to disallow any direct pushes to the default, master branch. The master branch is production-level code and should be reflective of this No code for in-progress features, extraneous debugging code and log statements, or code of poor quality in general should be in this branch. Any change that is required must be pushed to a branch other than master and then follow the merge workflow. This is important both from a software development point of view as well as a DevOps point of view as I will soon explain.
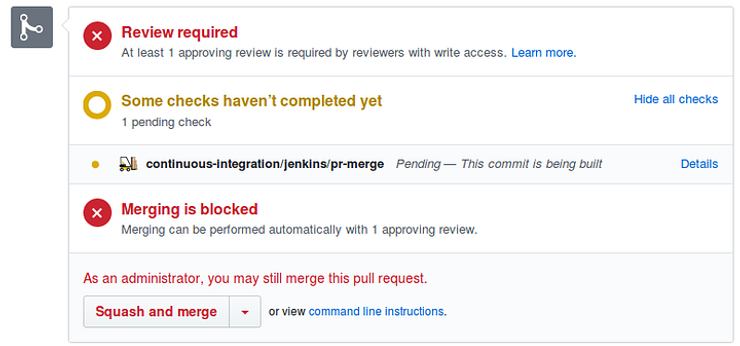
Once a pull request is created we send a notification on a messaging platform, slack in our case, and also email. This alerts all stakeholders that a change is planned and is being requested for merge. On the pull request, we add two checks that must be satisfied before it can be merged to master. These checks can be configured in the Git service such as Github in our case. The first check, a code review by a peer or lead must be done. Changes can be requested by the PR author, and once the changes are made to satisfaction, the pull request can be approved.
The second check is that of the Jenkins CI pipeline. The pipeline is triggered automatically using webhooks and if the pipeline runs successfully, the second check on the PR is satisfied. The successful CI pipeline run with stages such as automated tests, canary release, deployment dry runs, or others, indicates that the new changes will not break existing functionality and fulfills other deployment requirements as well. For a deeper dive into CI/CD tools, you can explore our blog on GitHub Actions vs. Bitbucket Pipelines vs. GitLab CI vs. Tekton.


With the CI pipeline for the PR successful, a snapshot of the build artifact as well as docker image, if the repository has a Dockerfile, is created and pushed to the Nexus OSS repository. For public repositories, the docker image is pushed to docker hub. This snapshot version is named using the PR number and build runs, e.g. PR-5–1. This helps to easily track which snapshot belongs to which PR.
Once the PR is merged into master, another Jenkins pipeline is triggered. This time a release is created and pushed to Nexus, and the release versions are bumped based on the previous ones. These release versions are tagged on the git repository, and updated within the project repository in files such as helm chart YAML, package.json, or another version file.
As a practice, we maintain a .version file in our repository for easily tracking the current version. And a homegrown utility that calculates the version to use on release.
Based on SemVer principles, if a new version has backward compatible or incompatible functionality changes, either the major or minor version number needs to be increased. This can be done by the developer in the .version file. And in the CD pipeline, the new version is based on either the latest git tag or the version file. Which ever holds the greater version, is used. The utility in the CD pipeline only bumps the patch version.
Repository Structure
Following GitOps principles, we maintain a configuration repository that is separate from the code repository. This means the build artifact from the code repository is reused across our different environments such as staging and prod, and we can easily promote any particular build version by easily updating our Configuration repo. In the case of a Kubernetes-based environment, the configuration repo will hold a YAML manifest where we can simply update the docker image version that should be used. For more information on continuous integration and deployment, you can read our blog on practical introduction to CI/CD/CT in DevOps. We will discuss GitOps and Configuration repos in more detail in a separate blog post.
Conclusion
In this blog post, I’ve discussed an overview of some of the best practices for git versioning that we use at Stakater. These best practices allow us to do collaborative development and continuous integration and delivery for our Kubernetes-based environments, based on DevOps principles. These also allow us to have visibility on our release process and make it flexible to upgrade and rollback releases. If you’re looking to streamline your Kubernetes operations and ensure secure, efficient deployment processes, consider exploring our Stakater Cloud or our Kubernetes Platform Assessment services for more tailored solutions.


